LVS目前除了本身的NAT、DR和TUN模式,还有淘宝开源的fullnat模式,个人了解(待确认)LVS在各大公司的使用情况是:
百度 – BVS(现淘宝的 普空 之前在百度搞得类似fullnat项目,未开源) 结构是fullnat模式+ospf等价多路径
阿里 – LVS(fullnat模式,已开源)结构是fullnat模式+ospf等价多路径,通过交换机ospf的一直性hash来避免session不一致的情况
腾讯 – TWG(也是类似于fullnat的项目,未开源)结构是fullnat模式+ospf等价多路径,通过LVS集群定期同步来实现session一致
LVS在小米的业务前端已经使用几年时间,从最开始的DR模式,到现在部分使用fullnat模式,整体上还是不错的:
DR模式下:CPU E3-1230 V2 @ 3.30GHz + 32G + Intel 82580 Gb网卡 + sata盘:单台极限pps能跑到接近200W,应对电商的抢购活动完全没有压力
但最近也现一些问题:抢购时入站流量将Gb网卡跑满,导致丢包;在HA模式下,主机宕机之后需要advert_int 秒(keepalived 配置项)来切换至备机,也就是说在切换的过程中,服务是不可用的;而且现有结构下,无法线性横向扩展(一个VIP只能由一台服务来提供服务),只能通过提升机器配置来应对流量的上涨
为了解决上面这些问题,所以我们开始尝试LVS(DR)通过ospfd,做lvs集群,实现一个VIP,多台LVS同时工作提供服务,不存在热备机器,如图:
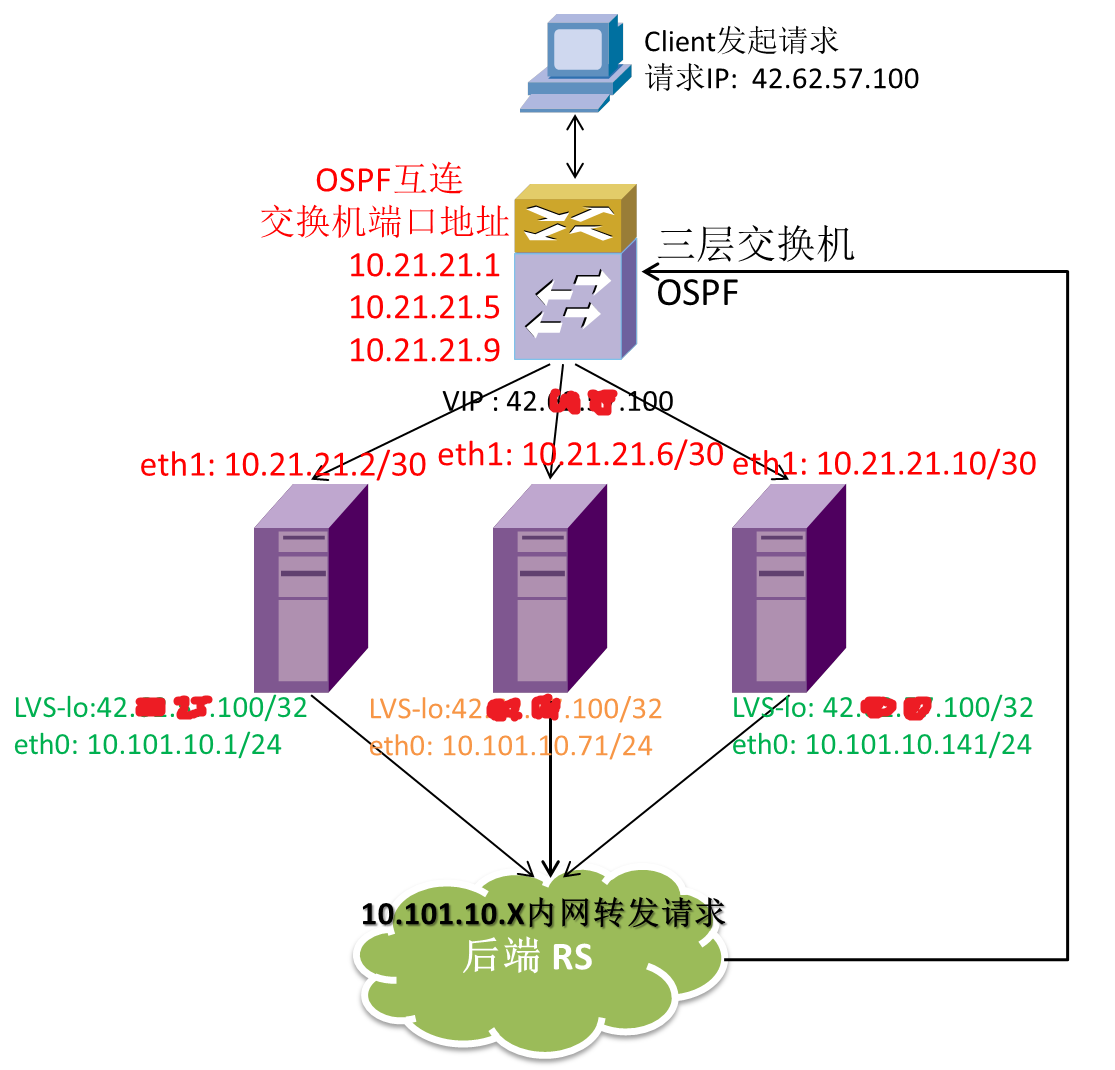
用户的访问过程是:
用户请求(VIP:42.xx.xx.100)到达三层交换机之后,通过对原地址、端口和目的地址、端口的hash,将链接分配到集群中的某一台LVS上,LVS通过内网(10.101.10.x)向后端转发请求,后端再将数据返回给用户,整个会话完成
Cluser模式的最大优势就在于:
- LVS调度机自由伸缩,横向线性扩展(最多机器数受限于三层设备允许的等价路由数目 maximum load-balancing );
- LVS机器同时工作,不存在备机,提高利用率;
- 做到了真正的高可用,某台LVS机器宕机后,不会影响服务(但因为华3设备ospfd调度算法的问题,一台宕机会使所有的长连接的断开重连,目前还无法解决;思科的设备已经支持一至性哈希算法,不会出现这个问题)。
部署过程:
1. 配置三层设备的ospf(这里以华3的设备为例):
交换机与LVS机器互连的端口号分别为2/9/0/19 2/9/0/20 2/9/0/21
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
interface GigabitEthernet2/9/0/19 //交换机与LVS机器连接的端口 port link-mode route //路由接口 ip address 10.21.21.1 255.255.255.252 ospf timer hello 1 ospf timer dead 4 ospf network-type p2p //OSPF网络类型 ospf 2 router-id 10.21.254.253 //进程ID 路由ID default-route-advertise always //始终下发默认路由 maximum load-balancing 6 //定义最大的ECMP条目,也就是最多能连接的LVS数量 area 0.0.0.0 //区域IP network 10.21.21.0 0.0.0.3 network 10.21.21.4 0.0.0.3 network 10.21.21.8 0.0.0.3 |
第二个端口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
interface GigabitEthernet2/9/0/20 //交换机与LVS机器连接的端口 port link-mode route //路由接口 ip address 10.21.21.5 255.255.255.252 ospf timer hello 1 ospf timer dead 4 ospf network-type p2p //OSPF网络类型 ospf 2 router-id 10.21.254.253 //进程ID 路由ID default-route-advertise always //始终下发默认路由 maximum load-balancing 6 //定义最大的ECMP条目 area 0.0.0.0 //区域IP network 10.21.21.0 0.0.0.3 network 10.21.21.4 0.0.0.3 network 10.21.21.8 0.0.0.3 |
第三个端口:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
interface GigabitEthernet2/9/0/20 //交换机与LVS机器连接的端口 port link-mode route //路由接口 ip address 10.21.21.9 255.255.255.252 ospf timer hello 1 ospf timer dead 4 ospf network-type p2p //OSPF网络类型 ospf 2 router-id 10.21.254.253 //进程ID 路由ID default-route-advertise always //始终下发默认路由 maximum load-balancing 6 //定义最大的ECMP条目 area 0.0.0.0 //区域IP network 10.21.21.0 0.0.0.3 network 10.21.21.4 0.0.0.3 network 10.21.21.8 0.0.0.3 |
2. LVS的ospf配置:
LVS机器两张网卡,一个与交换机用做ospf互连,一个与内网连接
安装ospf软件:
|
1 |
yum –y install quagga |
a.配置zerba.conf
|
1 |
vim /etc/quagga/zebra.conf |
|
1 2 3 |
hostname lvs-p1 ###这个名字每台要不一样,另外两台用的p2和p3 password xxxxxx enable password xxxxxx |
b.配置ospfd.conf
与交换机的通讯主要是这个进程,通过它将自己的VIP(42.xx.xx.100)声明出去
|
1 |
vim /etc/quagga/ospfd.conf |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
hostname lvs-p1 ### 另外两台用的p2和p3 password 8 5ubmJdMAQxXbs ### 这个密码是123456 enable password 8 4fcJB8NFa.0v6 log stdout log syslog service password-encryption ! ! interface eth0 ! interface eth1 ip ospf network point-to-point ip ospf hello-interval 1 ip ospf dead-interval 4 ! interface lo ! router ospf ospf router-id 10.21.21.2 ###各台的ID不能一样,这里我用的ospf互联地址做为ID,另外两台使用10.21.21.6 和10 log-adjacency-changes ! Important: ensure reference bandwidth is consistent across all routers auto-cost reference-bandwidth 1000 network 10.21.21.2/30 area 0.0.0.0 ###这里是宣告自己的ospf互连地址和VIP地址,新增地址就是在这里添加 network 42.xx.xx.100/32 area 0.0.0.0 ! line vty ! |
其它的LVS机器ospf的配置修改一下hostname和 ospf router-id就可以了
开启转发:
|
1 2 |
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf sysctl –p |
开启服务:
|
1 2 |
/etc/init.d/zebra start /etc/init.d/ospfd start |
|
1 2 3 4 5 6 |
[root@lg-pt-lvs02 ~]# netstat -lntpu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:2604 0.0.0.0:* LISTEN 27071/ospfd tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1596/sshd tcp 0 0 127.0.0.1:2601 0.0.0.0:* LISTEN 27006/zebra |
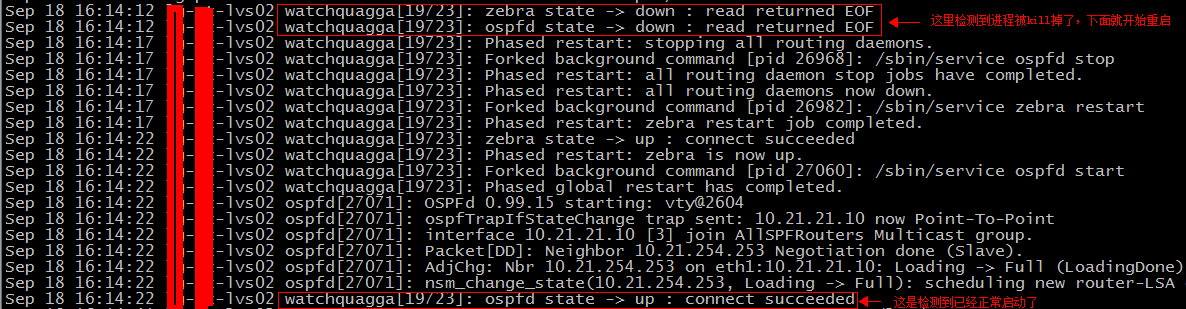
可以看到这两个进程都启起来了;系统日志里,可以看到
![]()
说明已经找到ospf邻居,正常宣告地址了
再在每台机器的LO上绑上宣告的VIP:
|
1 |
vi /etc/sysconfig/network-scripts/ifcfg-lo:01 |
|
1 2 3 4 5 6 |
#for lvs-dr-real-server DEVICE=lo:01 IPADDR=42.xx.xx.100 NETMASK=255.255.255.255 ONBOOT=yes # |
![]()
这时候可以ping一下42.xx.xx.100这个地址,能通就说明ospf已经配置成功了
在测试时遇到一个问题,我们在LVS机器上新添加地址时,需要Reload ospfd这个进程,查看启动脚本,他里面的Reload就是stop再start,所有宣告的IP会断开,再启起来
但是通过telnet 连接机器的ospfd管理端口添加新地址会立即生效,且不影响现有的IP,所以写了个脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#!/bin/bash $ip=$1 pswd="123456" expect -c " set timeout 30 eval spawn -noecho telnet 127.0.0.1 2604 expect \"Password:\" send \"$pswd\r\" expect \" *>\" send \"enable\r\" expect \"Password:\" send \"$pswd\r\" expect \" *#\" send \"configure t\r\" expect \" *(config)#\" send \"router ospf\r\" expect \" *(config-router)#\" send \"network $ip/32 area 0.0.0.0\r\" expect \" *(config-router)#\" send \"w\r\" send \"exit\r\" send \"exit\r\" send \"exit\r\" interact" >/dev/null |
保存为addip.sh;
这里是需要先安装expect,再执行:
|
1 2 |
yum -y install expect sh addip.sh x.x.x.x(IP)就可以直接添加宣告VIP,不用Reload ospfd进程了 |
Quagga软件还提供了类似supervise的进程监控软件watchquagga,可以监控并重启本机的zebra和ospfd进程,下面使用watchquagga来启zebra和ospfd服务:
|
1 2 |
killall zebra ospfd #先把这两个进程停了 watchquagga -adz -r '/sbin/service %s restart' -s '/sbin/service %s start' -k '/sbin/service %s stop' zebra ospfd |
大家可以手动kill掉ospf进程测试一下:
3. 接下来就是LVS(DR)的配置:
|
1 |
yum -y install keepalived ipvsadm |
因为使用了ospf来选择路由,LVS上所有的VIP是用32位掩码绑在lo的网卡上的,所以在配置keepalived.conf时,主配置项vrrp_instance、等都不需要了,只需要配置virtual_server对应的后端就行了
我们服务器上就只配置了:
|
1 |
vi /etc/keepalived/keepalived.conf |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
virtual_server 42.xx.xx.100 80 { delay_loop 6 lb_algo wlc lb_kind DR protocol TCP real_server 10.101.10.14 80 { weight 6 TCP_CHECK { connect_port 80 connect_timeout 20 nb_get_retry 3 delay_before_retry 5 } } } |
三台LVS的keepalived配置完全一至,再启动keepalived:
|
1 |
/etc/init.d/keepalived start |
然后再到后端的realserver上把VIP绑到LO网卡上,
|
1 |
vi /etc/sysconfig/network-scripts/ifcfg-lo:01 |
|
1 2 3 4 5 6 |
#for lvs-dr-real-server DEVICE=lo:01 IPADDR=42.xx.xx.100 NETMASK=255.255.255.255 ONBOOT=yes # |
|
1 |
ifup lo:01 |
再打开转发:
|
1 2 |
echo "net.ipv4.ip_forward = 1" >> etc/sysctl.conf sysctl –p |
到此就都配置完成了,用户访问42.xx.xx.100这个IP,会落到10.101.10.14这台realserver上,再直接返回给用户
51 Comments
路过顶一下
很高端的赶脚
DR模式下:CPU E3-1230 V2 @ 3.30GHz + 32G + Intel 82580 Gb网卡 + sata盘:单台极限pps能跑到接近200W,应对电商的抢购活动完全没有压力
我觉得有压力啊,瓶颈在新建连接,我自己测试82576的千兆网卡新建连接在10W以内。PPS到是差不多。
DR模式如果在有人攻击,应该扛不住吧
synflood攻击的话,肯定是不如Fullnat的synproxy功能的;
ddos的话应该是差不多的效果;
lvs本身防攻击的效果就有限额……
与网络设备互相建邻居,为什么要使用P2P的方式?时间调整是为了能更早发现邻居问题吗?如果处理不过来ospfd进程丢包是不是会导致ospf震荡,影响流量呢?
单三层有单点在,楼主有双三层的拓扑吗?感谢!
关于“但因为华3设备ospfd调度算法的问题,一台宕机会使所有的长连接的断开重连,目前还无法解决”,愿闻其详
谢谢
一台宕机后,后端的机器数量改变,ospf算法里的基数就改变了,所有连接所对应的后端都会重算,变更后端的连接就会断开,重新建连了
LVS调度算法改为源IP能解决不?
你好,有没有lvs fullnat cluster 安装配置,分享一下
http://kb.linuxvirtualserver.org/images/c/c8/LVS%E6%93%8D%E4%BD%9C%E6%89%8B%E5%86%8C.zip
官网的是lvs-v1的,很旧了
v2 v3的在https://github.com/alibaba/LVS
你好,最近我也在测试LVS-OSPF集群,在(但因为华3设备ospfd调度算法的问题,一台宕机会使所有的长连接的断开重连,目前还无法解决;思科的设备已经支持一至性哈希算法,不会出现这个问题)这个测试的时候,发现跟您说的不太一样,我们测试CISCO交换机在一台服务器宕机后,所有长连接都会断开重连。不知是否因为交换机型号不同,或是IOS版本导致,能否告知下CISCO哪个系列支持或者IOS版本,跪谢!
cisco只有在N7K nexus 5之前版本支持一致性哈希算法(据我说知也就仅限于nexus平台的特定较老的版本),在N7K后续的版本中又取消这个feature。原因是如果支持一致性哈希的话LB设备出现异常或增加LB设备后会造成流量不均的情况。OSPF+LVS这种架构主要是用于横向扩展LVS的性能,最大8台LVS(switch有支持16的ECMP,不过还要看LINUX是否支持16条的ECMP)。至于想实现单台LB出现异常长连接不断的话,在LB同步session是比较好的选择(某公司已经在做出来)。但这样其实也解决不了上述流量不均的问题。希望可以帮到你:)
该属性为系统默认自带的,还是需要配置命令启用呢?
一致性哈希算法在cisco中应该怎么配置啊?…不是自带的;
那这个该怎么配置啊?麻烦请教下,路由交换机就是N7K
可有做成功?
[...] and SYNPROXY 的介绍 ,后来回头再看了遍之前在小米运维部的NoOPS博客见到那篇LVS-ospf集群(可以说是LVS NAT [...]
好文。
请问,使用ospf,如果其中一台LVS宕机,是不是所有连接都被断开重连?因为hash变了。
不好意思,没有注意看评论,有这方面讨论了。
我们公司也在用fullnat,据我了解,阿里并不是依赖交换机一致性hash,他们正在开发lvs之间的session同步,预计两个月后完成。
不错,赞一个
请问lvs间session同步这个代码有开源么?我们现在部署ospf+lvs遇到了这个问题,暂时找不到好的解决办法
阿里实现了吗?有没有源代码出来啊?
多谢分享,一直使用DR模式,有时间也测试一下fullnat。
请问小米的网关有没有做集群部署
有的
请问小米的网关和LVS是部署在同一台机器还是分开部署,
我们现在的问题是分开部署,会耗费比较多的公网ip,想把两个集群搞在一起
我们是分开部署的
cisco设备采用一致性哈希算法就解决了长连接断开重连的问题?我看过了一致性哈希算法的概念,但还是不清楚为什么一致性哈希可以解决这个问题。
”sata盘:单台极限pps能跑到接近200W“ 用什么工具测试的请问
用的netperf,可以看看下面这篇文章:
http://www.ibm.com/developerworks/cn/linux/l-netperf/
用了fullnat之后,客户端和真实服务端的time_wait都堆得特别多,用V1、V2都有同样的情况,有人遇到过么?在真丝服务器上抓包看到lvs给realserver一下子发5~10个ack包,但realserver并没有回应
嗯,我们也是遇到time_wait(还有fin_wait)非常多的情况,但local-ip够多的话(我们是一台机器用一个C类地址,253个),观察实际环境下wait过多的影响不大
一台机器绑定253个c类地址解决time_wait?
交换机上配置的:
network 10.21.21.0 0.0.0.3
network 10.21.21.4 0.0.0.3
network 10.21.21.8 0.0.0.3
和 10.21.21.2/6/10 这三个 IP 有关系吗?
这几个IP都是交换机与lvs机器的点对点IP,ospf互联用的
抢购时入站流量将Gb网卡跑满,上10G的网卡咋样呢?这个架构有点复杂,另外IDC或者运营商有1G或者10G的接入光缆?
我们是有10Gb的升级计划,现在正在评估测试10Gb网卡,完成后会更新到blog上来的
我们大部分的IDC都是上联光纤接入的,理论最大10Gb
麻烦问下楼主:
DR模式不是不能跨网段运行的吗?我参照楼主这个结构访问不到real svr,请问楼主有什么关键点没?
请问下:
后端RS的数据包是怎么出去返回给client的?我这里死活不成功。求助
问下,你们现在的lvs fullnat 又做session 同步么?默认的session 同步模块看了下,只是 cip +vip+dip 的组播发送,就算切换了,lip 也是不一样的 ip 一样会断。
这里涉及了交换机的配置?
问下,我已经做出来了。问题是客户直接公网IP返回,还是经过lvs,像nat一样返回?
你好
我交换与机器网卡做的trunk,一路VLAN给的私网互联地
址,另外一个VLAN给的是公网ip,机器环回口给的一个32位的公网ip作为VIP,交换上有了均衡路由,但是外网访问VIP的时候不通,不知道是为什么~~
目前发现问题是,lvs虽然是双活,但是只有一个lvs上面有负载,其它一个lvs 是闲着状态,只有关掉其中一个有负载的lvs后,连接才会跑到另外一个lvs上,目前lvs服务器只有硬件配置一个高,一个低,难道和配置高低有关系?
目前发现问题是,lvs虽然是双活,但是只有一个lvs上面有负载,其它一个lvs 是闲着状态,只有关掉其中一个有负载的lvs后,连接才会跑到另外一个lvs上,目前lvs服务器只有硬件配置一个高,一个低,难道和配置高低有关系
ospf如下:
10.0.0.141/32 ospf 10 101 172.16.100.2
172.16.200.2
rs用私网地址,私网网关必须和公网网关再同一台设备上么?