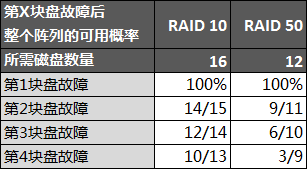
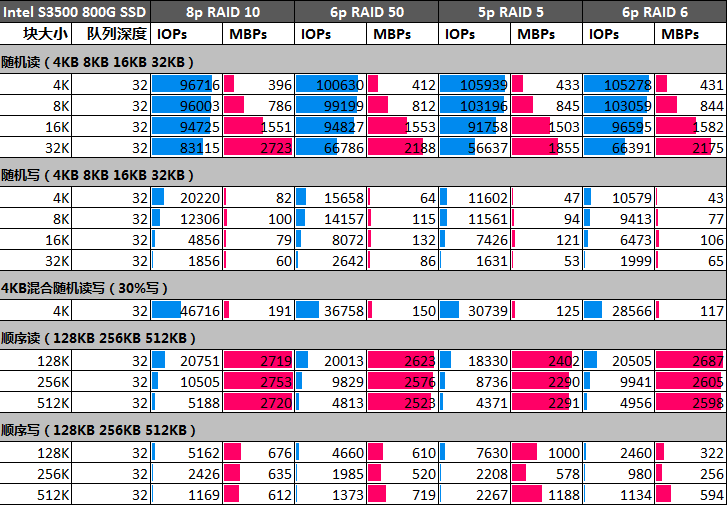
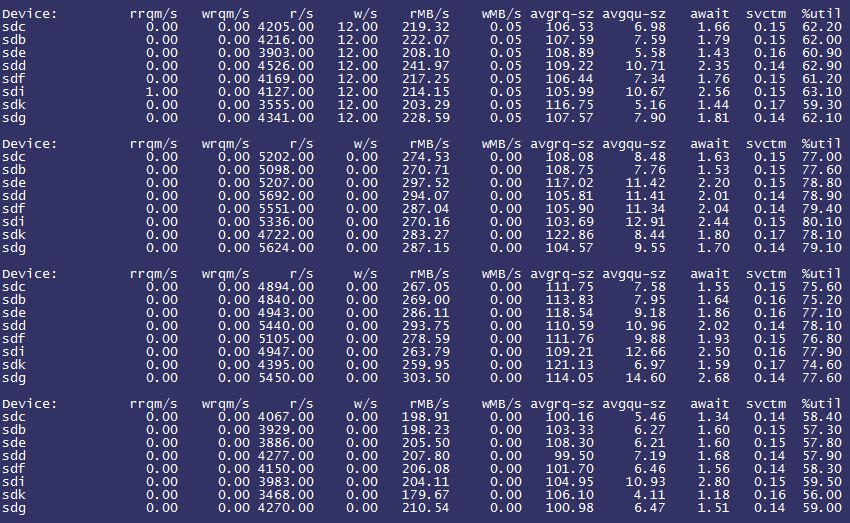
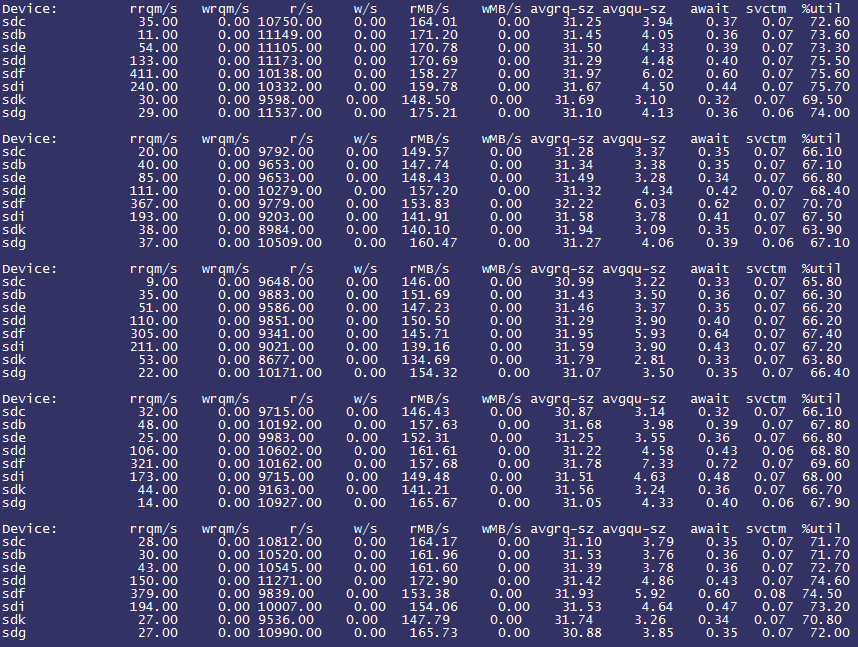
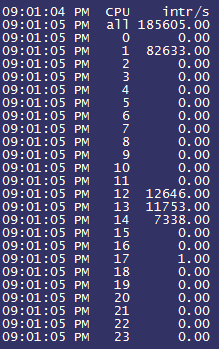
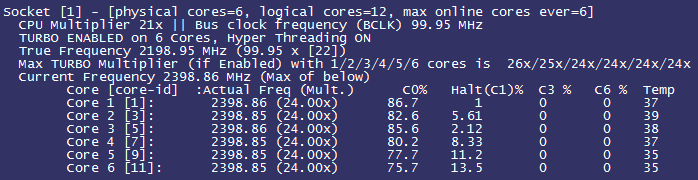
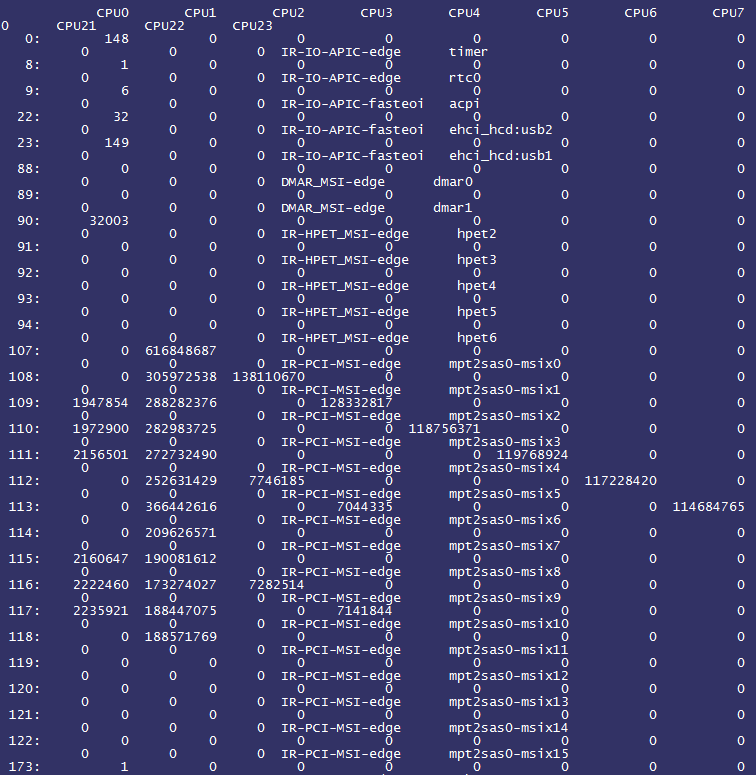
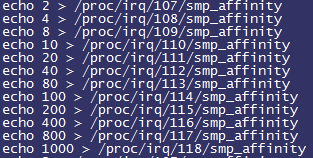
每个公司大概都有一个“稳定性保障一号位”,在不断翻车中持续进击。
当技术手段不足以提供确定性解法的时候,一般就需要祭出“压实主体责任”这最后的一招了,充分调动每个人在组织中的能动性,以达成目标。而设置“一号位”通常是压实主体责任的第一环。
在 IT 领域,稳定性保障一直属于最不具备“确定性解法”的 topic,防不胜防,大家的解法也是五花八门,你有你的张良计,我有我的过墙梯。奈何常在河边走,哪能不湿鞋。打脸来的太快,这怕是对负责稳定性保障的技术人心态的最好写照了。
此外,稳定性保障工作,低频、高危。平时不显山露水,但是一旦发生大故障,一号位首当其冲,如果功夫没有做在平时,那就是被架在火上烤,在接下来的稳定性整改运动中,基本可以引咎辞职了。
稳定性 case 的影响可大可小,对应的责任也可大可小,取决于:
1. 承载的业务的重要性
2. 故障时刻的损失程度
2. 舆论的传播面
3. 品牌的影响度
4. 法律法规和监管的要求
5. 公司管理制度的要求
因此,随着以上几个因素的不断变化,公司在某个阶段,对稳定性保障提出更高的要求,对一号位的要求也会有不同。但总体而言,一号位的职责总结如下。
## 稳定性一号位的职责是什么
1. 承担责任
也俗称“背锅”,稳定性既然是技术领域的重要工作,对业务产生着重大影响,那么结果不符合预期,一号位需要承担责任,这是完全说得通的,有压力才有动力。但承担责任不是目的,核心还是通过一号位的机制,将整个稳定性保障工作体系化的规划起来。
2. 制定合理的目标并确保目标可被分解和量化,让所有人参与进来
目标是否合理,体现在两个方面,一是稳定性目标是否和业务效果紧密挂钩,IT 系统是否稳定,是由其承载的业务是否正常来决定的,唯有如此,才能真正体现IT系统赋能业务支撑业务的本质价值,避免自嗨式目标、听不懂的目标;二是系统的稳定性,够用就好,目标过高,投入产出不成正比,要知道目标过高,每前进一小步,所花费的人力物力时间成本,会呈数量级放大。
目标设置不合理,首先是对自己的业务、IT 现状认识不全面,没有深入去思考,其次是盲目攀比,听闻坊间传说几个9,就随手拍脑袋,比他再高一个点!关于稳定性目标,可以延伸阅读[《服务稳定性保障的五大误解》](https://mp.weixin.qq.com/s/G8W2cqVKqT2AlZxWWXU0Rw)。
承担责任,也是一个技术活,要讲究方式方法,不是死扛硬抗,个人英雄主义。制定了目标,要有机制拆解到 IT 系统的各个技术参与方并且清晰的量化,确保参与方都能使上劲。具体可以参考[《SLO新解,一种行之有效的故障处理方法》](https://mp.weixin.qq.com/s/dA-7o-7wv0x24pDf0TXJag)。
3、确定预算
撇开成本谈保障工作,属于无源之水无本之木。稳定性保障一号位,在定好目标之后,接下来就是要确定和锁定预算。预算不单纯指直接负责稳定性保障任务的 headcount,也包括公司对于资源使用率要求、架构升级专项任务的预算、行业先进工具引入的费用预算、业务研发团队在稳定性工作上的参与度等等。
在一个大的组织,在年度预算开启前,确定好上面这些工作,是非常有挑战和考验稳定性保障一号位的综合能力。
4、建立技术保障体系
实际上是通过建立工具体系,做好两个事情:
- 不断提高稳定性保障的“确定性”:
>> 提高确定性的过程,就是不断兑现承诺、提升信心的过程,比如稳定性保障团队是否能在业务和用户感知之前发现问题,是否能给出故障解决的预期时间,能快速准确的评估故障的影响面,有行之有效的故障止损预案等。
- 不断降低稳定性保障工作的“门槛”:
>>要承认,现阶段处理故障,对工程师的经验要求太高了,既要有扎实的 troubleshooting 的能力,有强大的抗压能力,对各种工具平台熟练使用,还要对整体系统的架构、细节都非常熟悉,这就决定了这样富有经验的工程师总是很稀缺,难以批量培养,甚至于一旦离职或者转岗,容易出现青黄不接的现象。那么能不能把这些经验形成方法论,沉淀到工具中,形成套路,降低门槛就显得至关重要。
当然,随着微服务和云原生架构的更多采用,带来敏捷和高效的同时,使得整个IT系统的复杂度成数量级的上升,这与我们所追求的“确定性”、“低门槛”背道而驰。
1. 系统越来越复杂,以至于无法清晰的定义什么是真的故障,无法定义,那就更谈不上准确、及时的发现故障了,稳定性保障工作,直接输在了起跑线;
2. 数据量越来越大,信息过载的问题变得格外突出,技术团队在有限的时间里,无法有效、准确的提取关键信息,导致贻误战机,造成巨大的业务损失;
3. 稳定性保障,在整个行业范围,缺乏有效的方法论沉淀和产品化抽象,导致故障处理的各个环节,高度依赖工程师个体的经验,不具备复制性,难以持续改进,俗话讲,缺乏套路,门槛太高;
所以,如何通过技术手段,结合数据、流程,形成一套行之有效的稳定性保障打法,应对上面的挑战,所有的一号位共勉。
十年前,我从毕业到百度、小米、滴滴,从保障一个服务、到保障一个业务、再到保障全平台,scope 在变化,但是职责未变、初心未改。直到今天创立快猫星云,仍然是希望通过打造最好的Flashcat平台,为整个行业做出力所能及的贡献。
如果你有观点和解法,欢迎添加我的微信 laiweivic 探讨交流。
关于快猫星云
快猫星云,一家云原生智能运维科技公司,秉承着让监控分析变简单的初心和使命,致力于打造先进的云原生监控分析平台,结合人工智能技术,提升云原生时代数字化服务的稳定性保障能力。
快猫星云团队是开源项目夜莺监控的主要贡献者、项目管理委员会核心成员。夜莺监控是一款开源云原生监控分析系统,采用 All-In-One 的设计,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力,已有众多企业选择将 Prometheus + AlertManager + Grafana 的组合方案升级为使用夜莺监控。
夜莺监控,由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。
快猫星云产品介绍
- 一分钟视频介绍: https://flashcat.cloud/videos/flashcat.mp4
- Flashcat平台PPT: https://sourl.cn/G5iZCT
- Flashcat官网:https://flashcat.cloud
- 在线体验demo: http://demo.flashcat.cloud